죠니가 알려준 부스트 코스 강의를 듣다가 발견한 HTTP 관련 글을 해석하고 정리해보려고 합니다.
원문 : https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
An overview of HTTP
HTTP is the foundation of any data exchange on the Web and it is a client-server protocol, which means requests are initiated by the recipient, usually the Web browser. A complete document is reconstructed from the different sub-documents fetched, for inst
developer.mozilla.org
HTTP는 HTML 문서와 같은 자원들을 가져올 수 있게 해주는 프로토콜입니다. HTTP는 웹 상에서 이뤄지는 데이터 교환의 기초가 되고 HTTP는 client(일반적으로 웹 브라우저로부터 요청이 시작되는 client-sever 프로토콜입니다. text, layout description, images, videos, scripts 등과 같이 서버로부터 가져온 서브 문서들로부터 하나의 완전한 문서가 재구성됩니다. 즉, 브라우저의 한 화면은 text, images, videos 등등 서버에서 가져온 다양한 data들이 재구성되어 나타납니다.

client와 server는 스트림 데이터가 아닌 각각의 메시지를 서로 주고받으면서 통신합니다. 주로 웹 브라우저인 client가 보내는 메시지를 requests라고 부르고 그에 대한 응답으로 서버가 보내는 메시지를 response라고 부릅니다.
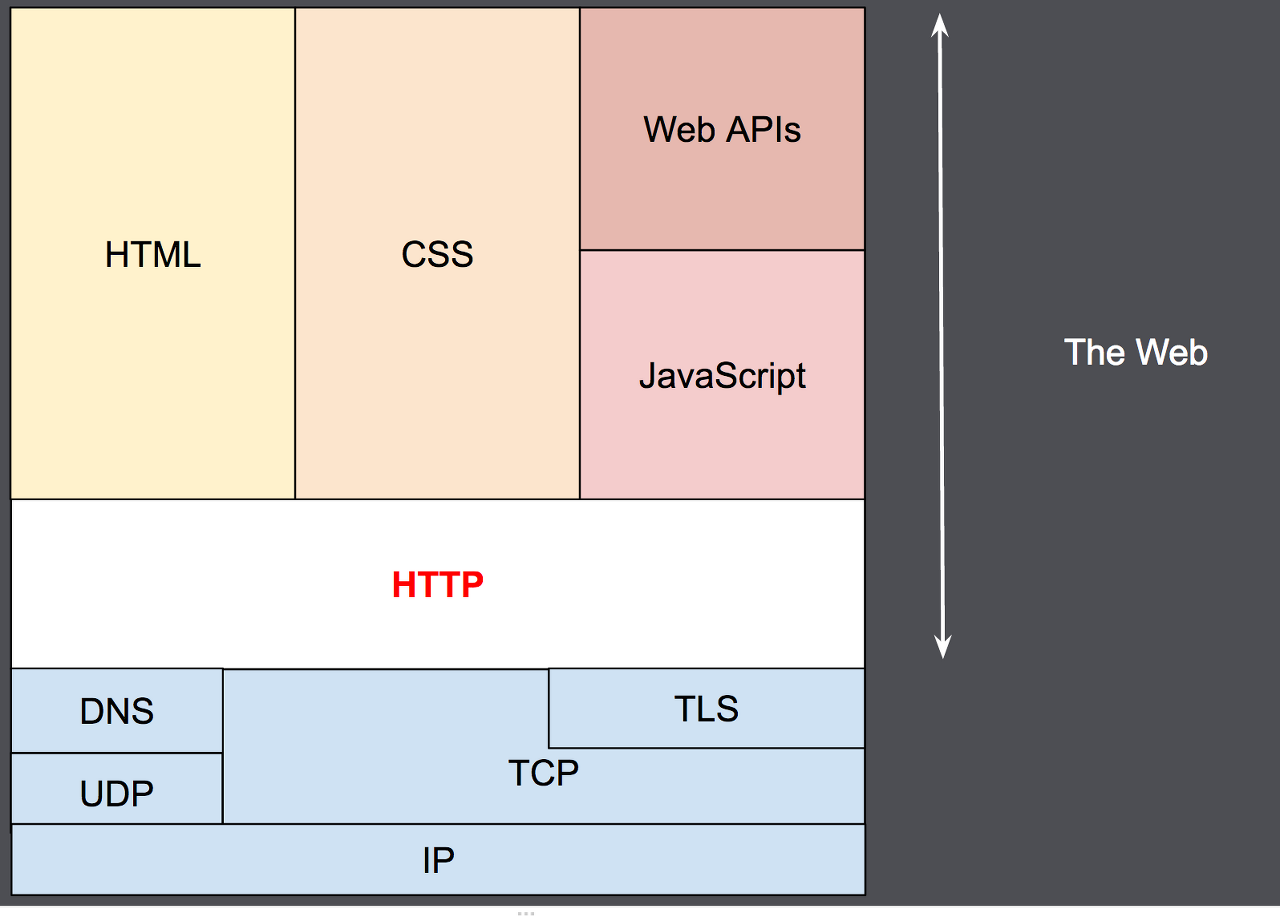
1990년대에 만들어진 HTTP는 시간이 지나면서 점점 발전한 확장 가능한 프로토콜입니다. HTTP는 이론적으로는 모든 신뢰 가능한 전송 프로토콜 위에서 작동 가능하지만 TCP 위에서(HTTPS의 경우 TLS로 암호화된 TCP 위에서) 작동하는 응용계층 프로토콜입니다. 이러한 확장성 때문에 HTTP는 서버로부터 hypertext 문서를 넘어 이미지나 비디오도 받아올 수 있고 서버로 HTML form result 같은 데이터를 보낼 수도 있습니다. 게다가 HTTP는 사용자의 요청에 따라 웹페이지를 업데이트하기 위해 문서의 일부만 가져올 수 있습니다. AJAX처럼 웹페이지의 일부분만 수정할 수 있다는 뜻인 듯..
HTTP 기반 시스템의 구성요소
HTTP는 client-sever 프로토콜입니다 : 요청은 하나의 개체인 user-agent (혹은 프록시)를 통해 보내집니다. 대부분의 경우 user-agent는 웹브라우저이지만 검색엔진 인덱스를 채우고 유지하기 위해 웹을 크롤링하는 로봇 등 무엇이든 될 수 있습니다.
각각의 요청들은 서버로 보내지고 서버는 그것을 처리하고 response라고 불리는 응답을 합니다. client와 server 사이에는 프록시로 불리는 수많은 개체들이 있는데 이들은 게이트웨이나 캐시 등의 다양한 역할을 수행합니다.

사실, 브라우저와 서버 사이에는 라우터나 모뎀 등과 같은 더 많은 컴퓨터들이 있습니다. 하지만 웹의 계층적 구조 덕분에 이들은 네트워크나 전송 계층에 숨겨져 있습니다. 그리고 HTTP는 가장 꼭대기, 응용 계층에 있어 이들을 신경 쓸 필요가 없습니다. 물론 하위 계층 레이어들이 네트워크 문제를 진단하는데 중요하지만 HTTP를 설명할 때는 필요가 없습니다.
Client: the user-agent
user-agent는 사용자처럼 행동하는 모든 도구입니다. 그 역할은 주로 웹브라우저가 수행하지만 종종 디버깅을 위한 프로그램일 수도 있습니다.
요청은 항상 브라우저에서 시작됩니다. 절대 서버에서 시작되지 않습니다.(server-initiated messages를 simulate하기 위한 몇 가지 메커니즘들이 몇 년 동안 추가되긴 하였지만 일반적으로 요청은 브라우저에서만 시작됩니다.)
웹 페이지를 나타내기 위해 브라우저는 페이지에 보여질 HTML 문서를 가져오는 요청을 보냅니다. 그리고 브라우저는 그 파일을 parse 해서 스크립트, CSS, images, videos 등등 페이지에 필요한 하위 자원들을 가져오는 요청을 추가로 보냅니다. 그다음 브라우저는 이 자원들을 잘 배치해서 하나의 완전한 문서인 웹 페이지를 보여줍니다. 브라우저가 실행한 스크립트 파일이 이후에 자원을 추가로 더 가져올 수 있고 브라우저는 상황에 맞게 웹 페이지를 업데이트할 수 있습니다.
하나의 웹 페이지는 하나의 hypertext 문서입니다. 즉, 한 문서에서 다른 문서로 링크가 걸려있고 그 문서로 이동할 수 있어(주로 마우스 클릭으로 이동 가능) 사용자가 그 링크를 통해 다양한 정보들을 볼 수 있습니다. 브라우저는 HTTP requests와 responses를 해석해서 실행함으로써 이러한 이동을 가능하게 합니다.
The Web server
통신 채널 반대편에는 서버가 있습니다. 서버는 사용자에게서 요청이 온 문서를 브라우저에 보여줍니다. 서버는 하나의 컴퓨터인 것으로 보입니다. 하지만 서버는 여러 서버의 집합일 수 있고 cache, DB server, e-commerce server 등과 같은 다른 컴퓨터들과 부하를 나누는 집합체의 일부일 수 있습니다. 서버가 온디맨드 방식으로 전체적으로 또는 부분적으로 문서를 생성하기 때문에 그렇게 보이는 것입니다. 즉, 서버는 여러 대의 컴퓨터의 집합이지만 온디맨드 방식으로 요청에 반응하기 때문에 하나의 컴퓨터처럼 보입니다.
서버는 하나의 컴퓨터일 필요가 없고 여러 개의 서버 소프트웨어 인스턴스가 동일한 컴퓨터에서 호스팅 될 수 있습니다. HTTP/1.1과 Host 헤더를 사용하면 여러 서버 프로그램이 하나의 IP 주소를 공유할 수 있습니다.
Proxies
웹 브라우저와 서버 사이에는 HTTP 메시지들을 전송해주는 수많은 컴퓨터와 기계들이 있습니다. 웹의 계층적 구조 때문에 그 컴퓨터와 기계들의 대부분은 전송, 네트워크, 물리 계층에서 동작하며 이들은 HTTP 레이어에서 transparent해지고(무슨 의미로 쓰인건지 잘 모르겠다) 퍼포먼스에 큰 영향을 미칩니다. 그 컴퓨터와 기계들 중에서도 응용 계층에서 동작하는 것들을 프록시라고 부릅니다. 그 프록시들은 서버로 가는 요청을 받아서 변경 없이 그대로 전송하면 transparent 할 수도 있고, 서버로 가는 요청을 변경한다면 non-transparent 할 수도 있습니다. 즉, 서버로 가는 요청을 변경하는지 그대로 보내는지에 따라 transparent or non-transparent 할 수 있습니다. (transparent : 있는데 없는 것 같아 보인다, 존재감이 없다, 숨겨져 있다 의 의미라고 함) 프록시는 아래와 같은 다양한 기능을 수행할 수 있습니다.
- 캐싱 (브라우저 캐시와 같이 공개되거나 숨겨질 수 있는 캐시)
- 필터링 (바이러스 검사나 자녀보호 필터링)
- 부하 분산 (여러 개의 서버가 각각 다른 요청을 처리하도록 함)
- 인증 (서로 다른 자원들에 대한 접근제어)
- 로깅 (로그 정보 기록)
HTTP의 기본 특징
HTTP is simple
HTTP는 간단하고 사람이 읽기 쉽게 만들어졌습니다. (HTTP/2에서 HTTP 메시지를 프레임 안에 캡슐화하여 살짝 복잡해졌지만 그래도 간단하다.) HTTP 메시지는 사람이 읽고 이해하기 쉬워서 개발자가 테스트 하기도 쉽고 초보자가 쉽게 배울 수 있습니다.
HTTP is extensible
HTTP/1.0에서 소개된 HTTP headers 때문에 HTTP는 확장성이 좋고 이것저것 실험해보기도 좋습니다. client와 server가 HTTP headers 양식에 서로 합의만 하면 새로운 기능이 쉽게 추가될 수 있습니다.
HTTP is stateless, but not sessionless
HTTP는 무상태 연결입니다. 즉, 한 client가 연속으로 server에 요청을 보내도 server는 그 요청들이 한 client에서 온 것인지 알지 못합니다. 이것은 온라인 쇼핑에서의 장바구니 같이 사용자가 자신의 정보가 유지되면서 웹 페이지를 이용하고 싶을 때 문제가 됩니다. 하지만 HTTP 자체는 무상태 연결이지만 HTTP 쿠키가 상태를 저장할 수 있는 세션을 사용하게 해줍니다. HTTP headers의 확장성을 이용해서 HTTP 쿠키를 통신 방식에 포함시키면 HTTP 요청들이 각각 세션을 생성하여 같은 context, 즉 상태를 공유할 수 있습니다. (HTTP 요청에 쿠키를 같이 넣어 보내서 상태를 유지한다는 뜻인 듯)
HTTP and connections
연결은 전송계층 담당이므로 기본적으로는 HTTP의 영역에서 벗어납니다. HTTP 밑에서 작동하는 전송계층 프로토콜이 꼭 연결 지향 프로토콜(TCP 같은)일 필요는 없지만 HTTP는 메시지를 안전하게 전송할 수 있도록 하는 (최소한 에러라도 표시해주는) 신뢰할 수 있는 전송계층 프로토콜을 필요로 합니다. 대표적인 인터넷 전송 프로토콜 중 TCP는 신뢰할 수 있고 UDP는 신뢰할 수 없습니다. 그래서 HTTP는 연결지향 프로토콜인 TCP 표준 위에서 작동합니다.
client와 server가 HTTP request/response 쌍을 교환할 수 있기 전에는 반드시 서로 신호를 주고받는 몇 가지 단계를 거쳐야 하는 TCP connection을 수립해야 했습니다. HTTP/1.0에서는 HTTP request/response 쌍을 처리할 때마다 새로운 TCP connection을 수립하는 것이 default입니다. 하지만 연속적으로 여러 개의 요청이 들어올 때는 하나의 TCP connection으로 처리하는 것이 더 효율적입니다.
이러한 단점을 개선하기 위해 HTTP/1.1에서 pipelining(구현하기 어려움)과 persistent connections를 도입하여 Connection 헤더를 이용해 TCP connection을 부분적으로 제어할 수 있게 했습니다. HTTP/2에서는 한 걸음 더 나아가 하나의 connection으로 메시지 다중 전송 기능을 추가하여 connection이 더 지속되도록 하고 더 효율적으로 사용할 수 있게 했습니다.
HTTP에 더욱 적합한 전송 프로토콜을 개발하기 위한 실험들이 진행 중입니다. 예를 들어, 구글에서는 UDP 기반의 더 신뢰 가능하고 효율적인 전송 프로토콜을 개발하기 위해 QUIC(퀵)이라는 프로토콜을 실험 중입니다.
내용이 길어서 나머지 내용은 다음 글에서 정리해야겠네요.
HTTP 내용에 대해 정리해보고 싶어서 시작한 글이었는데 영어 공부를 한 느낌이 듭니다.. 영어 실력이 부족해 어려운 내용이 아님에도 해석하는데 시간이 오래 걸렸습니다;;
공식 한글 번역본은 여기에서
https://developer.mozilla.org/ko/docs/Web/HTTP/Overview
HTTP 개요
HTTP는 HTML 문서와 같은 리소스들을 가져올 수 있도록 해주는 프로토콜입니다. HTTP는 웹에서 이루어지는 모든 데이터 교환의 기초이며, 클라이언트-서버 프로토콜이기도 합니다. 클라이언트-서버 프로토콜이란 (보통 웹브라우저인) 수신자 측에 의해 요청이 초기화되는 프로토콜을 의미합니다. 하나의 완전한 문서는 텍스트, 레이아웃 설명, 이미지, 비디오, 스크립트 등 불러온(fetched) 하위 문서들로 재구성됩니다.
developer.mozilla.org
'Web' 카테고리의 다른 글
| JWT(JSON Web Token) 란? (0) | 2021.01.13 |
|---|---|
| HTTPS는 왜 안전한가? (0) | 2020.11.28 |
| HTTP에 대해서(2) (0) | 2020.01.25 |
| Express로 만든 웹 사이트 heroku에 올리기 (0) | 2019.08.18 |



